Rigorous Software Engineering
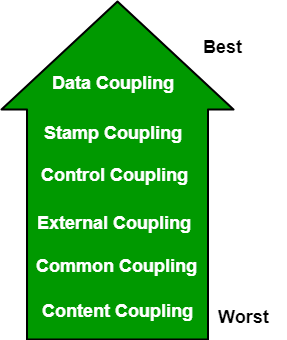
Coupling Link to heading
Coupling is the measure of the degree of interdependence between the modules. A good software will have low coupling.
- Data coupling - Modules exchanging elements, and the receiving end use all of them.
- Procedural coupling
- Class coupling
Data coupling Link to heading
dependency between modules: communicate y passing only data => data coupled. Components are independent of each other and communicate through date.
Problems:
- CHanges in data representation
- Unexpected side effects
- Concurrency
E.g. customer billing system
- access on public variables
- hide implementation details behind the interface (make private)
- don’t give links, copy references
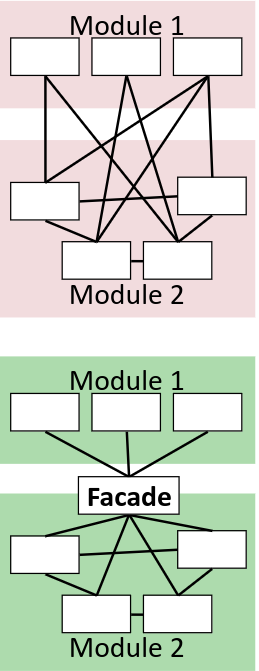
Facade Pattern Link to heading
- restricting and simplifying access
- provide single, simplified interface
- web browser API
Flyweight Pattern Link to heading
- maximizes sharing of immutable objects
- Invariant: if two objects are structurally equal, they are the same object
Procedural Coupling Link to heading
- Modules are coupled to other modules whose methods they call Problems:
- Changing a signature in the callee requires changing the caller
- Callers cannot be reused without callee modules Approach:
- Moving code, may reduce procedural coupling
- duplicating functionality
Observer Pattern Link to heading
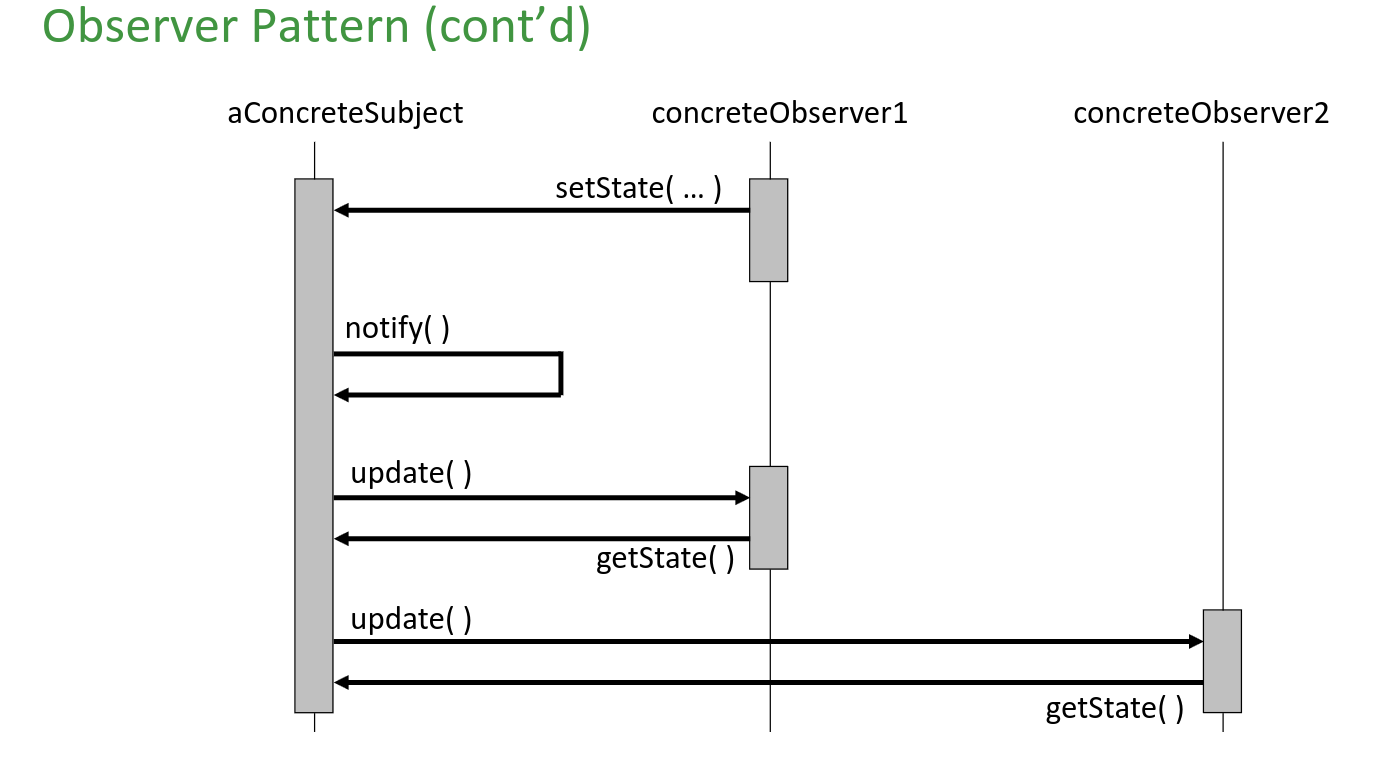
“Observer Pattern defines one-to-many dependency between objects so that when one object changes state, all of its dependents are notified and updated automatically.”
Aside from formal definition, Observer Pattern helps us to listen (subscribe) to a subject and be up-to-date whenever a change occurs.
Subjects are open for the Observers to subscribe, and does not know (nor care about) how they are implemented and vice versa.

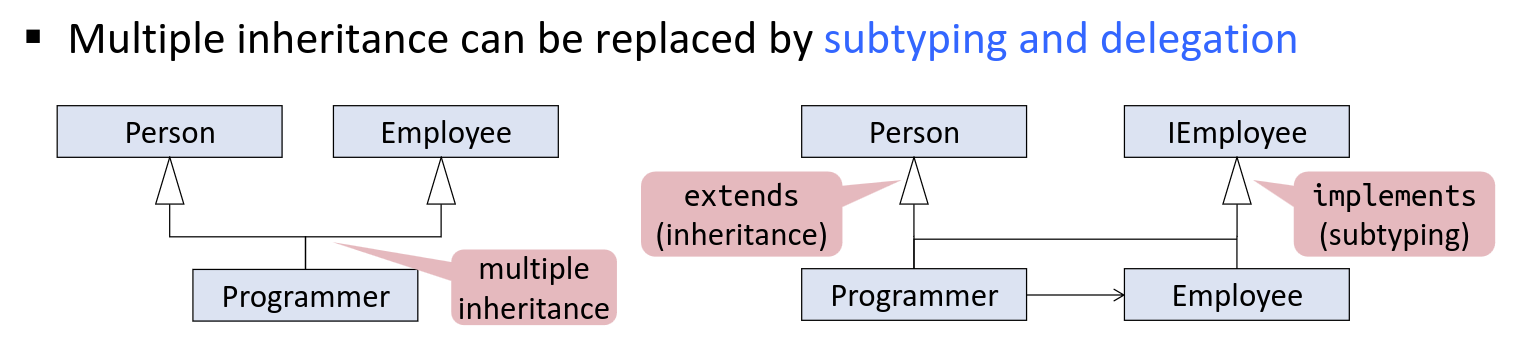
Class Coupling Link to heading
Inheritance couples the subclass to the superclass Solution:
- Delegation can be used to avoid coupling through inheritance
- Type Declaration, make as generic as possible
- Using interfaces (Instead of TreeMap, jut use Map, most general Supertype)
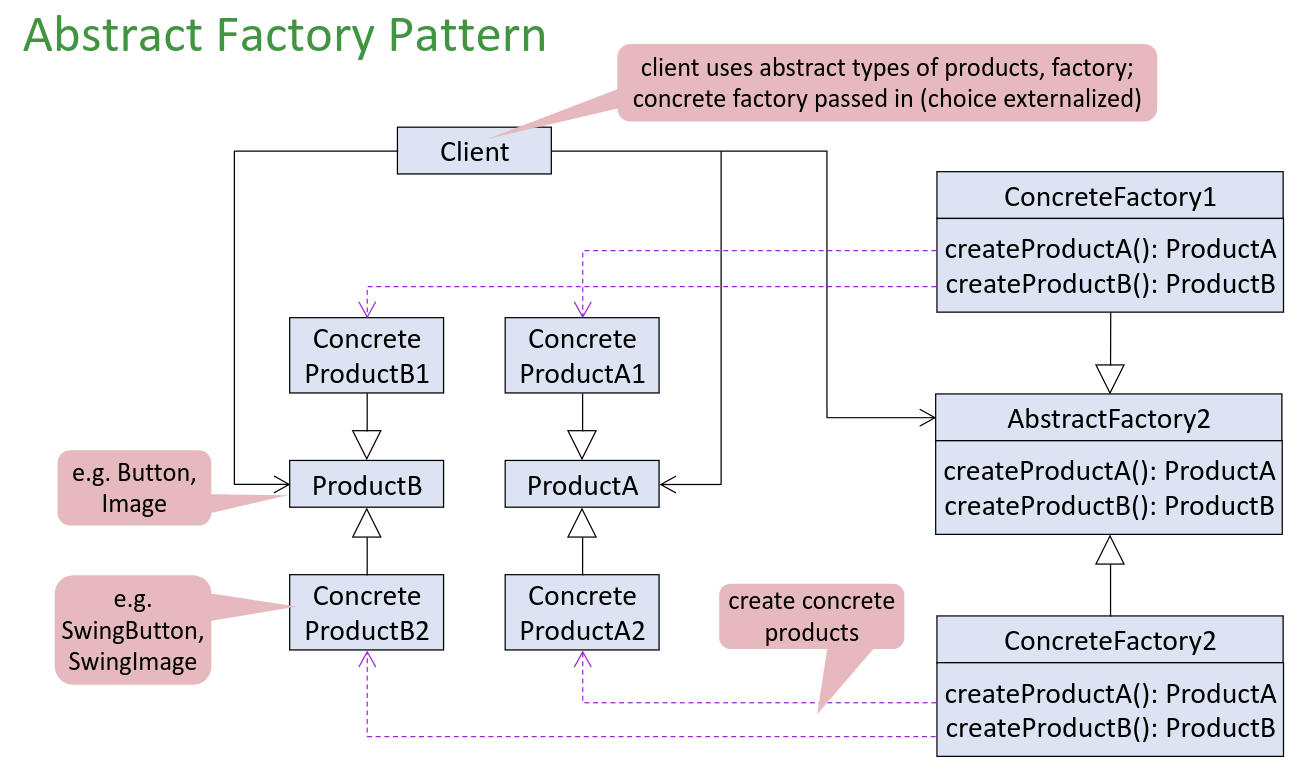
Abstract Factory Pattern Link to heading
Situation: Construction of families of objects
interface MealFactory {
Pizza createPizza(); // no inheritance needed
Burger createBurger(); // no inheritance needed
}
```java
Vegan Meal Factory Implementation
public class VeganMealFactory implements MealFactory {
@Override
public Pizza createPizza() {
return new VeganPizza();
}
@Override
public Burger createBurger() {
return new VeganBurger();
}
}
Non-Vegan Meal Factory Implementation Link to heading
public class NonVeganMealFactory implements MealFactory {
@Override
public Pizza createPizza() {
return new NonVeganPizza();
}
@Override
public Burger createBurger() {
return new NonVeganBurger();
}
}
Now it’s a factory of factories. Link to heading
- In the Factory Method pattern, a single method was responsible for creating a pizza. Here, we have separate methods for different types of pizzas and burgers, so the whole class is responsible.
- In the Factory Method pattern, Pizza and Burger needed to be of type Meal. Here, it’s not compulsory.
Client code Link to heading
MealFactory veganMealFactory = new VeganMealFactory();
MealFactory nonVeganMealFactory = new NonVeganMealFactory();
Pizza veganPizza = veganMealFactory.createPizza();
Burger veganBurger = veganMealFactory.createBurger();
Pizza nonVeganPizza = nonVeganMealFactory.createPizza();
Burger nonVeganBurger = nonVeganMealFactory.createBurger();
Since both VeganMealFactory and NonVeganMealFactory are of type MealFactory, can’t we just decide between them using a simple decider?
Meal Factory Decider Link to heading
public class MealFactoryDecider {
private MealFactoryDecider(){}
public static MealFactory decide(MealType mealType) {
switch (mealType) {
case VEGAN:
return new VeganMealFactory();
case NONVEGAN:
return new NonVeganMealFactory();
default:
throw new RuntimeException("Invalid type.");
}
}
}
Final Client Code Link to heading
MealFactory veganMealFactory = MealFactoryDecider.decide(MealType.VEGAN);
MealFactory nonVeganMealFactory = MealFactoryDecider.decide(MealType.NONVEGAN);
Pizza veganPizza = veganMealFactory.createPizza();
Burger veganBurger = veganMealFactory.createBurger();
Pizza nonVeganPizza = nonVeganMealFactory.createPizza();
Burger nonVeganBurger = nonVeganMealFactory.createBurger();
Summary Link to heading
The Abstract Factory Pattern is used to create families of related or dependent objects without specifying their concrete classes. In this example, we implement a MealFactory interface with methods to create different types of pizzas and burgers. We then create two factory classes, VeganMealFactory and NonVeganMealFactory, each responsible for creating vegan and non-vegan versions of these meals.
In contrast to the Factory Method pattern, which uses inheritance and a single method for object creation, the Abstract Factory pattern uses composition with multiple methods in the factory interface. This approach allows more flexibility, as you can decide between different factory implementations using a MealFactoryDecider.
This pattern is useful when you want to ensure your code is flexible and scalable, allowing you to easily add new types of meals without changing existing code.
Adaption Link to heading
Strategy Link to heading
The Strategy Pattern is a design pattern used in software engineering that allows you to define a family of algorithms, encapsulate each one, and make them interchangeable. This pattern lets the algorithm vary independently from clients that use them, making it a flexible way to change the behavior of a class by switching out its algorithm or strategy.
Strategy Pattern = Dynamic Method Binding (in OOP)
Key Concepts of Strategy Pattern Link to heading
- Encapsulation: Each strategy (algorithm) is encapsulated in its own class.
- Interchangeability: Strategies can be changed at runtime, allowing the behavior of an object to be modified without altering its code.
- Separation of Concerns: The pattern separates the algorithm from the host class, adhering to the Single Responsibility Principle.
Simple Example: A Cat Game Link to heading
Consider a game where a Cat class needs to switch its diet strategy. Initially, the cat follows a normal diet, but if it gains too much weight, it needs to switch to a weight-loss diet. The Strategy Pattern allows this change without altering the Cat class code.
Code Implementation Link to heading
- Define the Strategy Interface:
interface EatBehavior {
public void eat();
}
Implement Different Strategies:
public class NormalDiet implements EatBehavior {
@Override
public void eat() {
// normal food
}
}
public class LosingWeightDiet implements EatBehavior {
@Override
public void eat() {
// healthy food
}
}
Cat Class with Strategy: Link to heading
public abstract class Cat {
EatBehavior eatBehavior;
public Cat() {}
public void eat() {
eatBehavior.eat();
}
public void setEatBehavior(EatBehavior eb) {
eatBehavior = eb;
}
}
Client Code: Link to heading
Cat cat = new Cat();
cat.eat(); // Cat eats as usual.
cat.setEatBehavior(new LosingWeightDiet());
cat.eat(); // Cat eats with a healthier diet.
Visitor Pattern Link to heading
The Visitor pattern is a behavioral design pattern that lets you separate algorithms from the objects on which they operate. By using the Visitor pattern, you can add new operations to existing object structures without modifying their classes. Here’s a summary of the key concepts and components of the Visitor pattern:
Key Concepts Link to heading
- Separation of Algorithms and Objects: The Visitor pattern allows you to place new behavior into a separate class called a visitor, instead of modifying existing object structures. This makes it easy to introduce new operations without altering existing code.
- Double Dispatch: The pattern uses a technique called double dispatch to determine the appropriate method to execute. This means that a method call is determined by both the visitor and the element that is being visited.
Components Link to heading
- Visitor Interface: Declares a set of visit methods for each type of element in the object structure.
- Concrete Visitor: Implements the visitor interface and defines specific behavior for each type of element.
- Element Interface: Declares an accept method that takes a visitor as an argument.
- Concrete Elements: Implement the element interface and the accept method, which calls the visitor’s method corresponding to the element class.
- Object Structure: A collection of elements that can be visited by the visitor.
Benefits Link to heading
-
Ease of Adding New Operations: Adding new operations is straightforward since you only need to create new visitor classes without modifying existing element classes.
-
Single Responsibility Principle: The pattern encourages the separation of concerns by allowing related behaviors to be grouped together in a visitor class.
Drawbacks Link to heading
-
Adding New Element Types: Adding new element types becomes challenging, as you need to update all existing visitors to handle the new element.
-
Complexity: The pattern can introduce complexity, especially if the object structure is large or frequently changes.
Example Use Cases Link to heading
- Compilers and Interpreters: Used to traverse and apply operations to abstract syntax trees. Document Processing: Used to apply operations to elements within a document, such as formatting or converting.
Conclusion Link to heading
The Visitor pattern is particularly useful when you need to perform operations on objects of different classes that make up a structure. It allows you to define new operations without changing the classes of the elements on which it operates, making it a powerful tool for maintaining open/closed principle and facilitating future extensions of the codebase.
Documentation Link to heading
Why? Link to heading
Essential vs Incidental Properties Link to heading
Stable vs. Unstable Properties Link to heading
-
Stable Properties: These are aspects of the software that should not change during evolution because they are considered essential for the software’s correct functionality. Stability indicates a commitment to maintaining these properties to ensure consistent behavior across different versions or implementations.
-
Unstable (or Incidental) Properties: These are aspects that can change without affecting the core functionality of the software. They are not essential to the core purpose of the program and might be modified to improve performance, readability, or adaptability to new requirements.
Essential vs. Incidental Properties Link to heading
-
Essential Properties: These are the critical features or behaviors that must be preserved for the software to function correctly. In the context of the example, an essential property might be that the function returns the index of a found element in the array.
-
Incidental Properties: These are details that do not affect the main function of the software. They may include the method of implementation or specific optimizations, such as whether a search is done sequentially or in parallel, as long as the essential properties are maintained.
Invariants Link to heading
- What is given at the start? Can something ever be negative?
Overriding methods Link to heading
- Initialize the fields of an object when
the object is created or when the
fields are accessed for the first time?

Aliasing Link to heading
- several pointer point to the same object
What? Link to heading
- How to use the code => document the interface
- How does the code work => document the implementation
Client Link to heading
- Constructor
- Methods
- Public fields
- Supertypes
How to call a method?
- cbuf is non-null
- offset is non-negative
What does a method return?
- method returns -1 if not valid
- return between 0, len
How does it affect the state
- Heap effects
- other effects, like exceptions, does it block?
- time, space
Global properties
- list is sorted
- clint-visible invariants
- list is immutable
Backend Link to heading
- Data structure documentation is more prominent
- Implementation invariants
- Documentation of the algorithms inside the code
- justification of assumptions
Summary Link to heading
- Methods and constructors
- Arguments and input state
- Results and output state
- Effects
- Data structures
- Value and structural invariants
- One-state and temporal invariants
- Algorithms
- Behavior or code snippets
- Explanation of control flow
- Justification of assumptions

How? Link to heading
- Comments
- Types and Modifiers
- Effect systems (throw, try catch)
- Metadata (@NonNull)
- Assertions
- Contracts (invariants)
Testing Link to heading
Test Stages Link to heading
Parameterized Unit Tests:
- avoid boiler-plate code
- useful, when test data is generated automatically
- generic test oracles can be difficult
- still several test methods needed
Test Strategies Link to heading
Exhaustive Testing Link to heading
- Check everything
- sometimes not possible
Random Testing Link to heading
- can maybe miss an important bug, probability just too low
Functional Testing Link to heading
- Test each case of the specification
- Black box
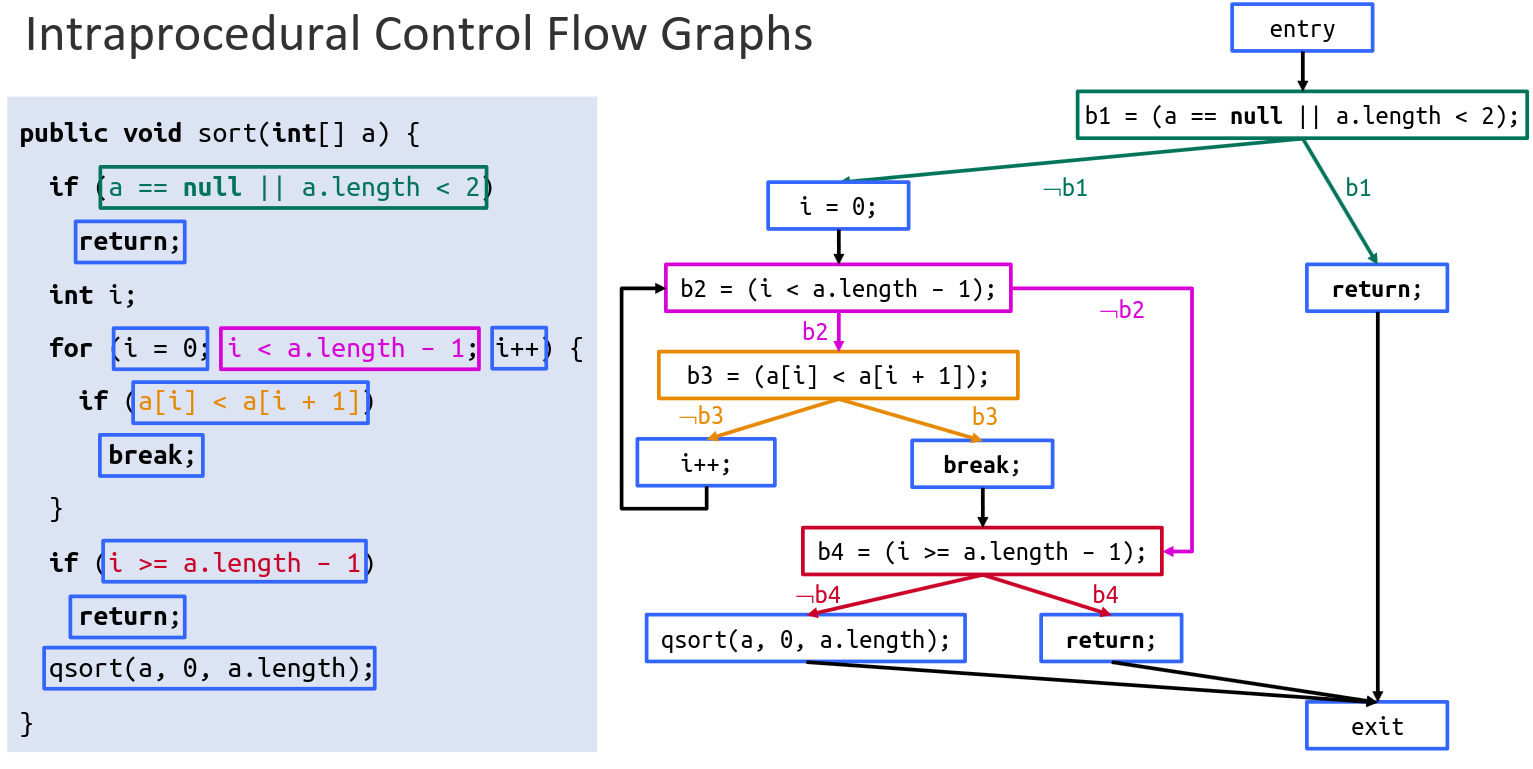
Structural Testing Link to heading
- White box
- Goal, Cover all the code, achieve high coverage
Summary Link to heading

Functional Testing Link to heading
Partition Testing Link to heading

Selecting Promising Values Link to heading

Combinatorial Testing Link to heading
- Semantic constraints potentially reduce the number of test cases
- Often without reducing coverage
- Identifying semantic constraints between inputs can help refine equivalence classes and increase coverage
- Still, often too many combinations remain
- Especially when there are many input values, e.g. for the fields of deep object structures
Pairwise-Combinations Testing Link to heading

Structural Testing Link to heading

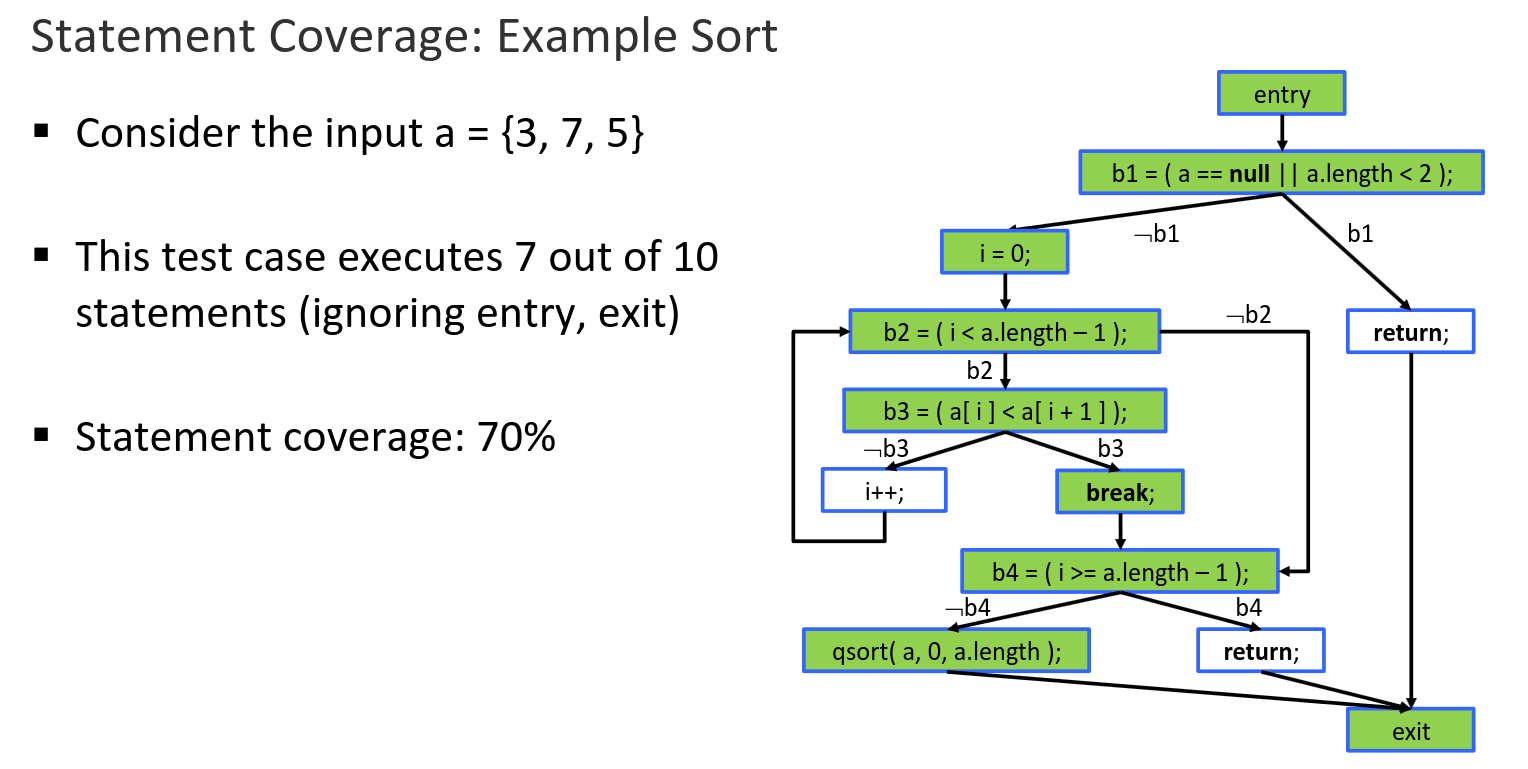

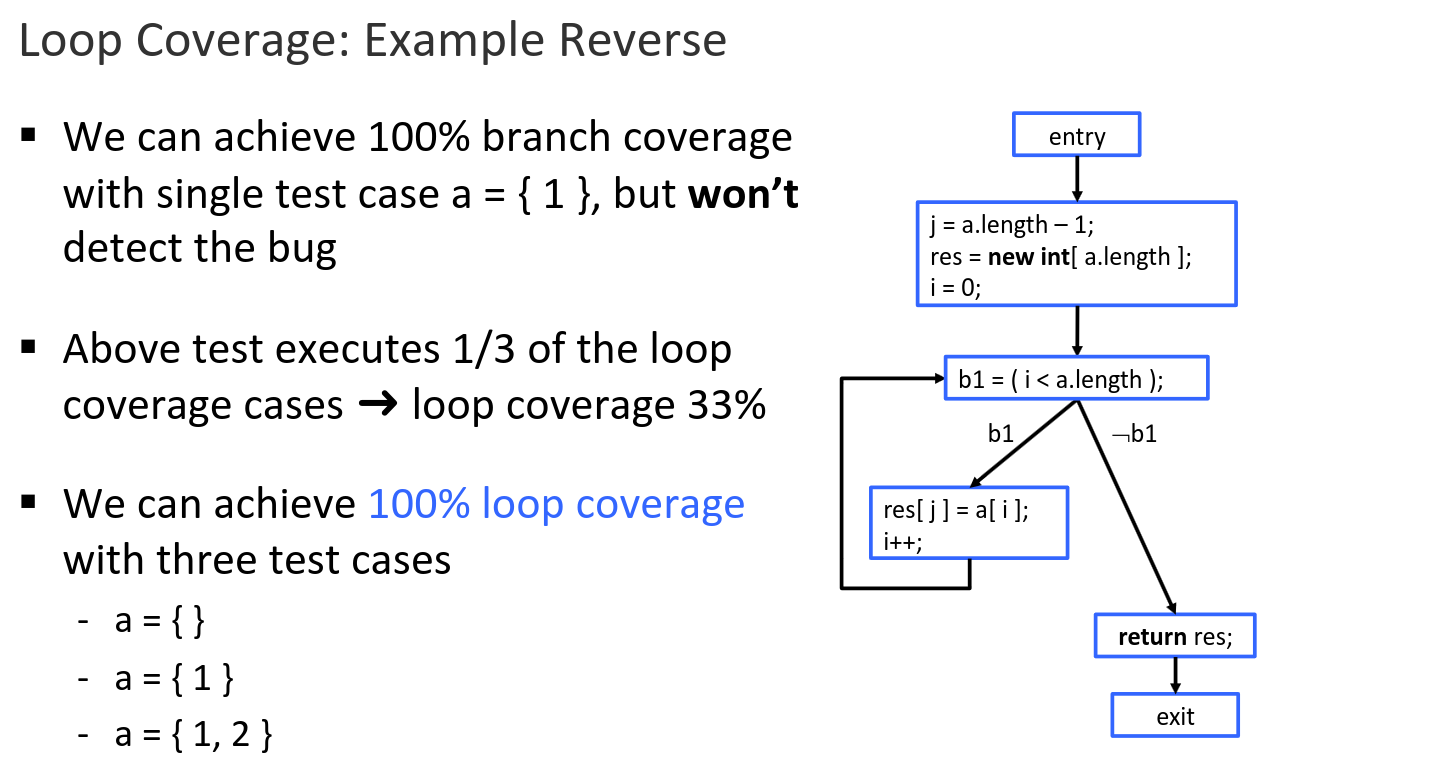
- Complete branch coverage implies complete statement coverage, but not th other way around
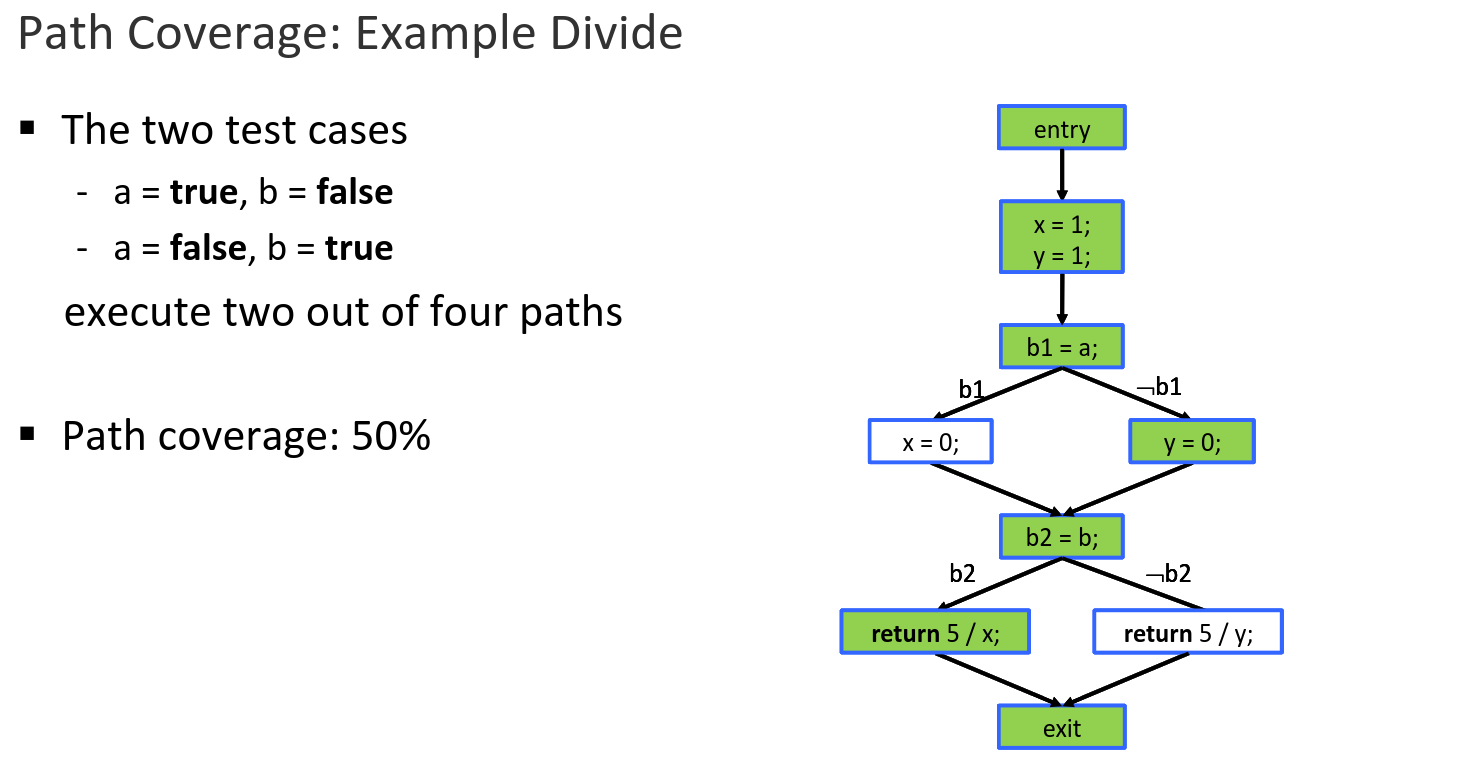
- Complete path coverage implies complete statement coverage, branch coverage, but not th other way around
- Complete path coverage is not feasible for loops
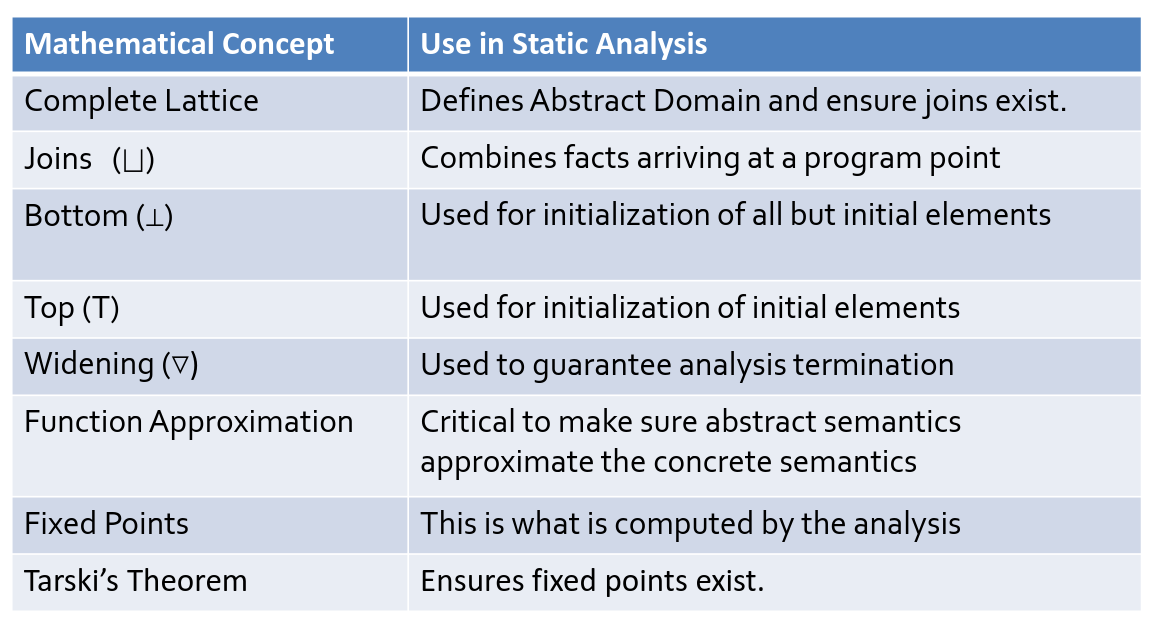
Analysis Link to heading
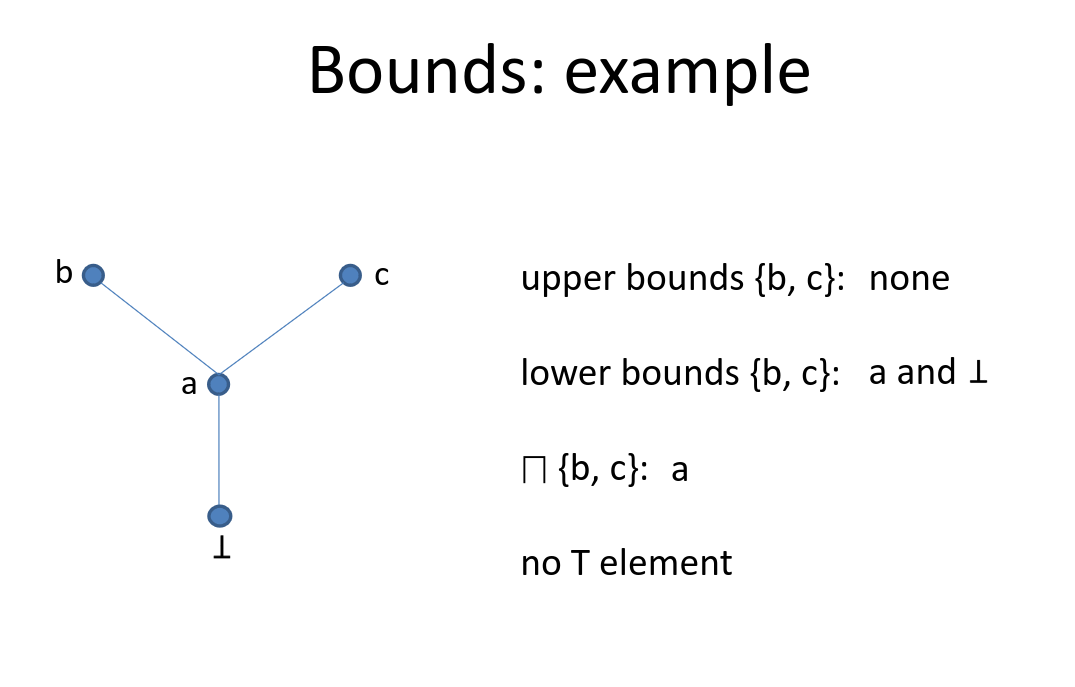
- Join is their (least upper bound)
Analysis Math Link to heading
- Partial order: binary relation on a set with properties
- Reflexive
- Transitive
- Anti-symmetric
- Poset fulfills this
- fixed point iff $f(x) = x$
- post-fixedpoint iff $f(x) \sqsubseteq x$
- 
- if $f’$ approximates $f$ then $f \sqsubseteq f'$

- C => Concrete, A, Abstract/Approximation.
- Abstraction gooooes to Approximation (alpha)
- Concretization gooooes to Concrete (gamma)
$$\forall z \in A : \alpha(F(\gamma(z))) \sqsubseteq_A F’(z)$$
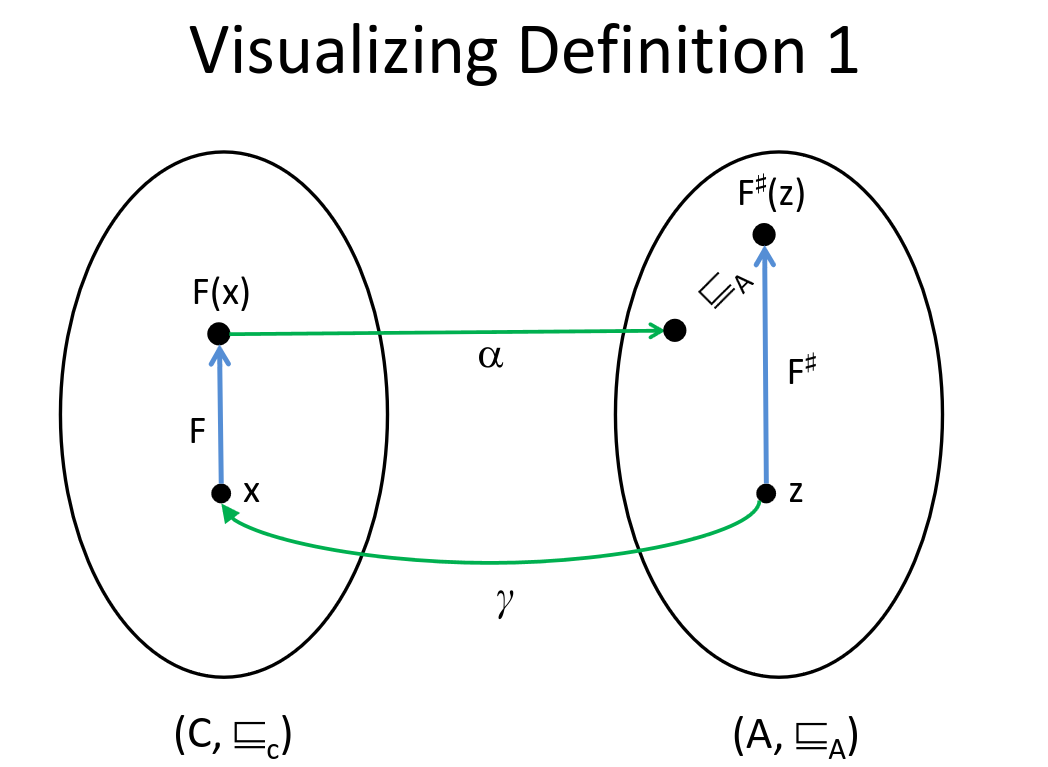 says is that if we have some function in the abstract that we
think should approximate the concrete function, then to
check that this is indeed true, we need to prove that for any
abstract element, concretizing it, applying the concrete
function and abstracting back again is less than applying the
function in the abstract directly
says is that if we have some function in the abstract that we
think should approximate the concrete function, then to
check that this is indeed true, we need to prove that for any
abstract element, concretizing it, applying the concrete
function and abstracting back again is less than applying the
function in the abstract directly

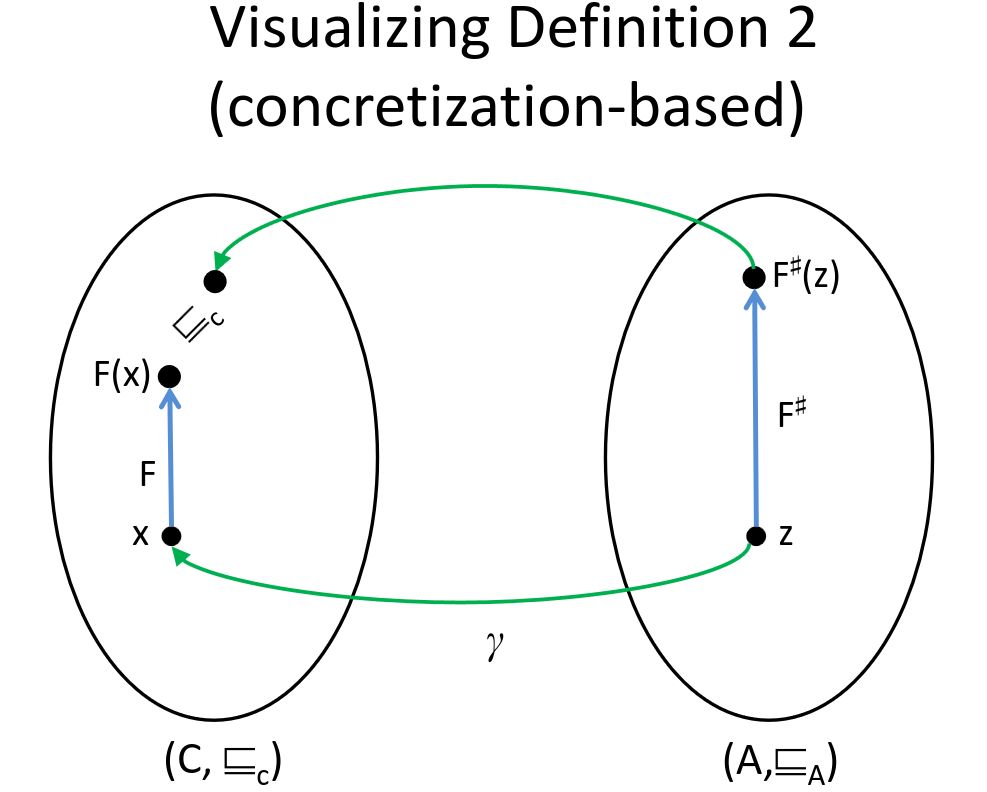
 if not monotone:
$$\forall z \in A : F(\gamma(z)) \sqsubseteq_C \gamma(F’(z))$$
if not monotone:
$$\forall z \in A : F(\gamma(z)) \sqsubseteq_C \gamma(F’(z))$$

Analysis Intervals Link to heading





$$ [a, b] \nabla_i [c, d] = [e, f] $$
where: $$\begin{align*} &\text{if } c < a, \text{ then } e = -\infty, \text{ else } e = a \ &\text{if } d > b, \text{ then } f = \infty, \text{ else } f = b \end{align*} $$
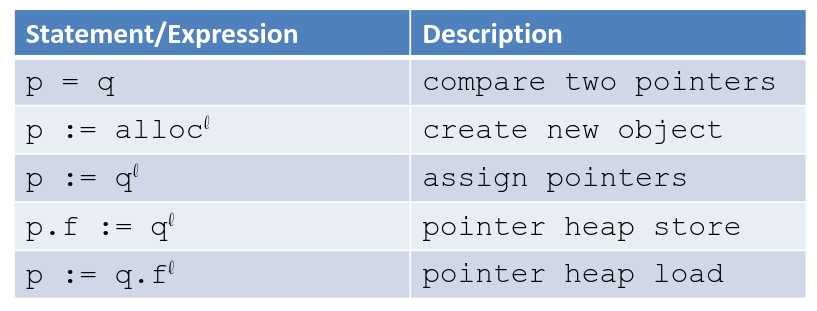
Analyis Pointer Link to heading

Flow sensitive: respects the program control flow
- a separate set of points‐to pairs for every program point
- the set at a program point represents possible may‐aliases on some path from entry to the program point
Flow insensitive: assume all execution orders are possible, abstracts away order between statements
- good for concurrency (if not too imprecise)
Determinism Link to heading
Sources of Unsoundness
- Unbounded Heap
- Compute finite set of abstract locations
- Using flow-insensitive points-to analysis
- Unbounded range of array indices
- Compute symbolic index constraints
- Using numerical abstractions
- Unbounded number of threads
Check (Abstract) Data-Race-Freedom Link to heading
- Compute all reachable abstract states
- Check if abstract states are data-race free (i.e. no read-write conflicts)
Questions Link to heading
- when are properties in a code stable